
Biostatystyka jest nauką zajmującą się zbieraniem, analizą i interpretacją danych w celu wydobycia informacji i wniosków na temat badanych zjawisk. Programowanie w języku R to popularne narzędzie w analizie danych, które umożliwia przeprowadzenie różnorodnych statystycznych obliczeń i wizualizacji. W tym wprowadzeniu do statystycznej analizy danych za pomocą R, zaprezentujemy kilka bardzo prostych przykładów kodów oraz ich wyników, aby pokazać, jak można wykorzystać R do analizy danych. Więcej na ten temat przeczytasz w naszym artykule „Porównanie oprogramowania statystycznego: R, Statistica, SPSS”.
Instalacja i uruchomienie R
Na początek musimy zainstalować R na naszym komputerze. Możesz pobrać najnowszą wersję R ze strony [https.//cran.r-project.org/](https.//cran.r-project.org/) i zainstalować ją zgodnie z instrukcjami dostępnymi na tej stronie.
Po zainstalowaniu R możesz uruchomić go poprzez kliknięcie ikony programu lub wpisując `R` w wierszu poleceń systemu operacyjnego.
Podstawy R
R to język programowania i środowisko do analizy danych, dlatego warto poznać kilka jego podstawowych zasad. Na początek możemy przypisać wartość do zmiennej, na przykład.
liczba <- 5
Teraz zmienna `liczba` zawiera wartość 5. Możemy wyświetlić jej zawartość za pomocą polecenia `print`.
print(liczba)
To wyświetli „5” na konsoli.
Przykład 1. Obliczanie średniej arytmetycznej.
Załóżmy, że mamy zestaw pomiarów temperatury w stopniach Celsiusza w ciągu pięciu dni.
temperatury <- c(20, 22, 19, 23, 21)
Teraz możemy obliczyć średnią arytmetyczną tych temperatur za pomocą funkcji `mean`.
srednia_temp <- mean(temperatury)
print(srednia_temp)
Otrzymamy wynik 21, co jest średnią arytmetyczną tych pięciu pomiarów temperatury.
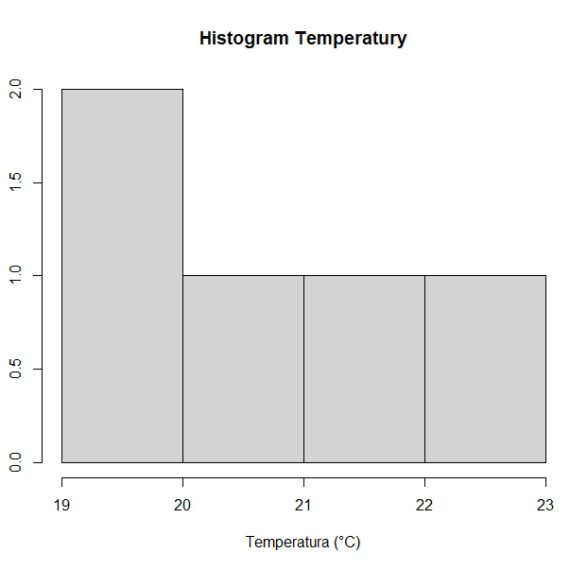
Przykład 2. Tworzenie wykresu histogramu.
Aby zobaczyć rozkład tych temperatur na wykresie histogramu, możemy użyć funkcji `hist`.
hist(temperatury, main=”Histogram Temperatury”, xlab=”Temperatura (°C)”, ylab=”Liczba Dni”)
To polecenie wygeneruje wykres histogramu, na którym można zobaczyć, jak często występują różne temperatury w naszym zestawie danych.
Przykład 3. Test t-studenta.
Załóżmy teraz, że mamy dwie grupy pacjentów i chcemy sprawdzić, czy istnieje istotna różnica w średnich wartościach jakiejś zmiennej między tymi grupami. Możemy użyć testu t-studenta do porównania średnich. Załóżmy, że mamy grupę kontrolną i grupę eksperymentalną i chcemy porównać średnie wyniki testu IQ.
grupa_kontrolna <- c(100, 105, 110, 115, 120)
grupa_eksperymentalna <- c(90, 95, 100, 105, 110)
Teraz możemy użyć funkcji `t.test`.
wynik_testu <- t.test(grupa_kontrolna, grupa_eksperymentalna)
print(wynik_testu)
Wynik testu t-studenta zostanie wyświetlony na konsoli i pomoże nam ocenić, czy istnieje istotna różnica między średnimi wynikami testu IQ w obu grupach.
To tylko krótka ilustracja tego, jak można wykorzystać R do prostych analiz danych. R oferuje znacznie więcej funkcji i możliwości, które pozwalają na zaawansowane analizy statystyczne, tworzenie wykresów, budowanie modeli itp. Dla osób, które nie mają doświadczenia w programowaniu i analizie danych, warto zacząć od prostych przykładów, takich jak te, aby zdobyć pewność i zrozumienie działania narzędzia.
R jest popularnym narzędziem wśród badaczy, naukowców i analityków danych, ponieważ jest bezpłatny, otwartoźródłowy i posiada bogatą społeczność użytkowników, co oznacza, że istnieje wiele dostępnych materiałów szkoleniowych i wsparcia. Jeśli jesteś zainteresowany analizą danych, R może być doskonałym narzędziem do rozpoczęcia przygody z tym obszarem.